Chapter 6 Patent Citations
This chapter focuses on the use of patent citations in patent analytics. Patent citations take two main forms:
- Citations of the scientific literature and other material such as news articles and websites, known as the Non-Patent Literature or NPL
- Citations of patent documents.
The patent citation system is similar to the familiar academic citation system. However, patent citations differ from academic citations because they limit the scope of what an applicant can claim to be new or novel or as involving an inventive step. As the American economist Suzanne Scotchmer reminds us when approaching the patent system applicants are ‘standing on the shoulders of giants’ (Scotchmer 1991). Put simply new applicants are confronted by the combined weight of the scientific literature, other material and existing patent applications that make up the prior art. The prior art limits the scope of what may be claimed by new applicants and is recorded in patent citations.
Citations within the patent system have become an important focus for research in fields such as econometrics, scientometrics and innovation studies. Citations of the non-patent literature are important focus of research because they help to reveal the closeness of the relationship between scientific research and innovative activity reflected in the patent system. Citations of patent documents are a focus of research because the number of citations that a patent document or patent family attracts is an indicator of social and economic value (A. B. Jaffe and Rassenfosse 2017). In addition, analysis of patent citations can lead to the identification of similar patent documents in a technology field, technology spillovers and technology trajectories.
A rich literature has emerged around patent citation analysis and we will highlight some of the key sources in the course of this chapter. Recent work by A. B. Jaffe and Rassenfosse (2017) provides an accessible and detailed overview of social scientific research involving patent citations. For those seeking to ground themselves in key literature the work by Adam Jaffe and Manuel Trajtenberg (A. Jaffe and Trajtenberg 1998, 2002), along with work by Bronwyn Hall (B. Hall, Jaffe, and Trajtenberg 2001; B. H. Hall, Jaffe, and Trajtenberg 2005; B. H. Hall and Harhoff 2012), Colin Webb and Helene Dernis at the OECD (Webb et al. 2005) and Dietmar Harhoff (Harhoff et al. 1999; Harhoff, Scherer, and Vopel 2003) are essential reading. For those interested in exploring the wider literature on patent citations a Lens public collection is available to assist readers with getting started. The collection is dynamic and will automatically update to the latest literature on patent citations.
In this chapter we will begin with the non-patent literature and move step by step through the issues that need to be considered when working with patent citation data. We will use examples from synthetic biology and CRISPR genome editing technology to illustrate approaches to the non-patent literature and patent citations and finish with recent research on identifying technology paths with citation data.
6.1 Non Patent Literature
Non-patent literature mainly takes the form of scientific publications such as journals, books, or chapters but also extends to other types of materials such as manuals, news reports, drawings and websites. As we will see below, viewed from a data science perspective the non-patent literature is that it generally takes the form of messy free text that requires extensive cleaning. However, from approximately 1980 onwards NPL has become an increasingly important focus for research.
For those seeking to track the emergence of research on NPL citations we will simply provide some useful way points. An important starting point of research on non patent literature is work by Carpenter, Cooper, and Narin (1980) on the links between basic academic research and patent activity using US patent citation data. This was followed in the mid-1990s by more detailed studies with larger scale data by Narin and collaborators (F. Narin, Hamilton, and Olivastro 1995; Francis Narin, Hamilton, and Olivastro 1997). This was accompanied by the growing proliferation of technology specific studies using citations such as work by Meyer (2000) on the relationship between nanoscale technologies and the cited literature. Citation based studies have tended to be heavily focused, for reasons of accessibility, on US patent data. However, in the mid-2000s work by Callaert, Looy, et al. (2006) examined 10,000 citations from the US and the European Patent Offices. This was followed by work to address the significant problems that exist with noise in NPL data using machine learning models (Callaert, Grouwels, and Looy 2011). The growing availability of NPL citation data is reflected in the growth of national and sectoral studies such as work by Fukuzawa and Ida (2015) exploring the links between scientific articles and patents for leading researchers in Japan. Recent work by Ding et al. (2017) has focused on the characteristics of scientific articles that facilitate knowledge flows between science and technology while Chen (2017) has explored the textual similarities between scientific articles and the contents of patent applications. Research by Rizzo et al. (2018) has focused on the closeness of publicly funded research and radical inventions in UK filings at the European Patent Office.
As this very brief set of way markers suggests, a significant body of work on diverse topics has emerged around the non-patent literature. While much of the original research focused on US patent data the creation of the EPO World Patent Statistical Database (PATSTAT) has made the wider non-patent literature available in a single table and served as a spur for research (Webb et al. 2005; Callaert, Grouwels, and Looy 2011; Karvonen and Kässi 2013). The recent PatentsView service from the USPTO now makes NPL citations available as a single table containing over 6 million raw references that can be freely downloaded. As such, data on non-patent literature citations is becoming more and more accessible for research.
We will consider the case of PatentsView in more detail below. However, one of the most important recent development are efforts by patent databases, led by the open access Lens database to electronically link literature databases and patent databases together.
6.2 Literature and Patent Citation Data with the Lens
As discussed in the chapter on the scientific literature, free electronic access to sources of the scientific literature is increasingly available through services such as Crossref, PubMed and Microsoft Academic Graph. The Lens has now developed a Scholar Search service that includes approximately 291.4 million scholarly works from PubMed, Crossref and Microsoft Academic. These records are then linked to citations in patent over 110 million patent documents covered by the Lens Patent Search. The importance of this approach is that it allows the user to navigate the non-patent literature linked to a particular record or to extract the cited literature from a record and create a collection to download and analyse. As we will also see, the recent PATCITE service also allows users to retrieve data on citations at scale.
To illustrate the possibilities opened up by combining the scientific and patent literature we will use the example of a patent search for synthetic biology and then move into exploration of the controversial subject of genome editing.
6.2.0.1 Retrieving Cited Literature from a Patent Search
We will begin with a simple patent search of the titles and abstracts for terms relating to synthetic biology in the Lens.
title: (“synthetic biology” OR (“synthetic genome” OR (“synthetic genomes” OR “synthetic genomics”))) OR abstract: (“synthetic biology” OR (“synthetic genome” OR (“synthetic genomes” OR “synthetic genomics”)))
You can try this exact query and example live by following this link. To make the most of the Lens we recommend that you register as a user (registration is free) as this will allow you to create collections for export.
At the time of writing this search generated 287 patent results and 776 cited works that can be viewed in the Cited Works panel as illustrated below:
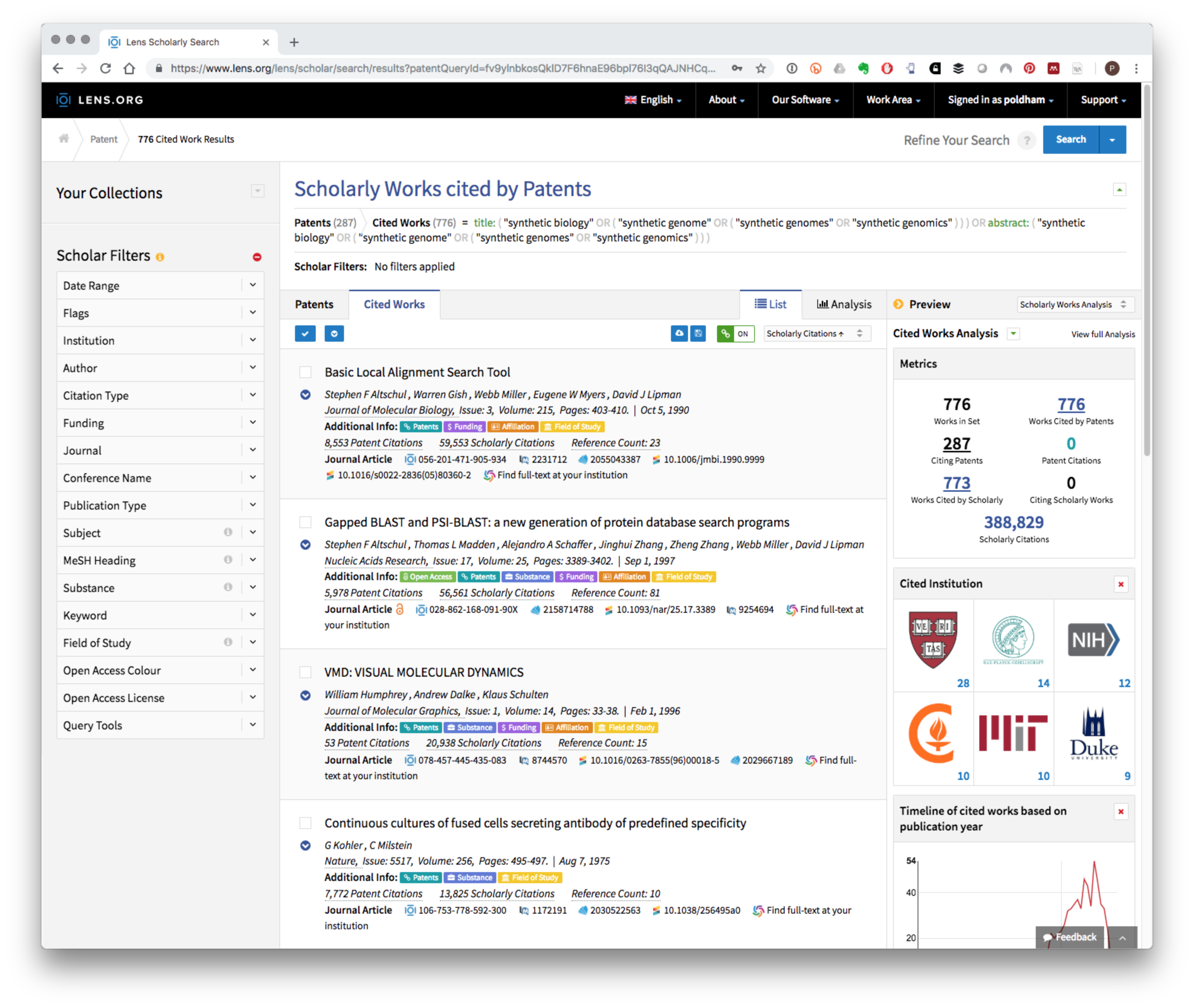
Registered users can create a public or private collection that can be shared with others and can also download the citation data up to a maximum of 50,000 records.
As an alternative to creating a collection an export button is provided in the Cited Works tool bar with options to download in CSV, RIS, Bibtex and JSON formats. The CSV (comma separated values) option is particularly suited to text mining or visualisation in tables while the popular Bibtex format will be useful for creating bibliographies for researchers writing in markdown. Table 6.1 displays a small selection of the results.
| Title | Publication Year | DOI |
|---|---|---|
| Pathway optimization and key enzyme evolution of N-acetylneuraminate biosynthesis using an in vivo aptazyme-based biosensor | 2017 | 10.1016/j.ymben.2017.08.001 |
| Transcriptome-based identification of the optimal reference CHO genes for normalisation of qPCR data | 2017 | 10.1002/biot.201700259 |
| The N-Acetylmuramic Acid 6-Phosphate Phosphatase MupP Completes the Pseudomonas Peptidoglycan Recycling Pathway Leading to Intrinsic Fosfomycin Resistance | 2017 | 10.1128/mbio.00092-17 |
| Efficient whole-cell biocatalyst for Neu5Ac production by manipulating synthetic, degradation and transmembrane pathways | 2016 | 10.1007/s10529-016-2215-z |
| Droplet immobilization within a polymeric organogel improves lipid bilayer durability and portability | 2016 | 10.1039/c6lc00391e |
A wide range of other fields are also available with the downloaded data such as authors, keywords, abstracts (where available), MeSH terms (Medical Subject Headings), Chemicals, source urls and the number of patent documents that reference an article among others. This is therefore a very rich set of data for further exploration.
Taking our small sample data for synthetic biology we can identify the articles that are the top cited in the patent dataset as displayed in Table 6.2. Note that the Referenced by Patent Count column refers to the total known count of patent documents citing the article. This measure will therefore generally favour older and foundational literature. This is revealed by the dominance of citations to the Basic Local Alignment Search Tool (BLAST) algorithm that is very widely used in biology.
| Title | Publication Year | Referenced by Patent Count |
|---|---|---|
| Basic Local Alignment Search Tool | 1990 | 8553 |
| Continuous cultures of fused cells secreting antibody of predefined specificity | 1975 | 7772 |
| A general method applicable to the search for similarities in the amino acid sequence of two proteins | 1970 | 6370 |
| Gapped BLAST and PSI-BLAST: a new generation of protein database search programs | 1997 | 5978 |
| Amino acid substitution matrices from protein blocks | 1992 | 2347 |
| Melamine Deaminase and Atrazine Chlorohydrolase: 98 Percent Identical but Functionally Different | 2001 | 1692 |
| Comparison of biosequences | 1981 | 1627 |
| Rapid and efficient site-specific mutagenesis without phenotypic selection | 1985 | 1568 |
| The tac promoter: a functional hybrid derived from the trp and lac promoters | 1983 | 1161 |
| One-step inactivation of chromosomal genes in Escherichia coli K-12 using PCR products | 2000 | 836 |
The availability of this type of data opens up a wide range of research opportunities and the maximum export of 50,000 records per query is likely to prove ample for most research purposes. These opportunities include.
- Refining search strategies by text mining the titles and abstracts and keywords of cited literature;
- Exploring networks of patent documents citing a key piece of literature;
- Examining available data on the funding of scientific research cited in patent documents as part of innovation studies;
- Assessing issues around the closeness of scientific research to inventions.
One illustration of patent exploration using our sample dataset might involve genome editing with CRISPR/CAS9. Patent activity in this field has attracted widespread attention following litigation between the University of California and the Harvard-MIT Broad Institute and the patent landscape linked to the CRISPR dispute is discussed in detail by Egelie et al. (2016) (see also Ledford (2016), Ledford (2017), Ledford (2018)). While not linked directly to patent activity, genome editing in humans using CRISPR/CAS9 has also recently attracted international media attention (Cyranoski and Ledford 2018).
Two key researchers in this field are Jennifer Doudna at Berkeley and Feng Zhang at the Harvard-MIT Broad Institute. Both appear in the NPL citations for our simple patent query for synthetic biology. By splitting the data so that each author name appears on its own row we can identify our authors of interest in the dataset as show in Table 6.3
| Lens ID | Author/s | Publication Year | Title |
|---|---|---|---|
| https://www.lens.org/018-893-049-787-145 | Jennifer A. Doudna | 2016 | New CRISPR-Cas systems from uncultivated microbes. |
| https://www.lens.org/049-383-529-000-174 | Jennifer A. Doudna | 2014 | Enhanced homology-directed human genome engineering by controlled timing of CRISPR/Cas9 delivery. |
| https://www.lens.org/009-802-337-761-385 | Feng Zhang | 2015 | Cpf1 is a single RNA-guided endonuclease of a class 2 CRISPR-Cas system. |
| https://www.lens.org/150-951-500-543-136 | Feng Zhang | 2013 | Double Nicking by RNA-Guided CRISPR Cas9 for Enhanced Genome Editing Specificity |
In Table 6.3 we see four publications by the key researchers cited in the sample dataset. Clicking on one of the links provides access to details on the records and also to patent documents that cite the literature at the Lens. In Figure 6.1 we have used the record in the third row of Table 6.3 above. In Figure 6.1 we can see the publication record and also the 170 patent documents that cite this paper.
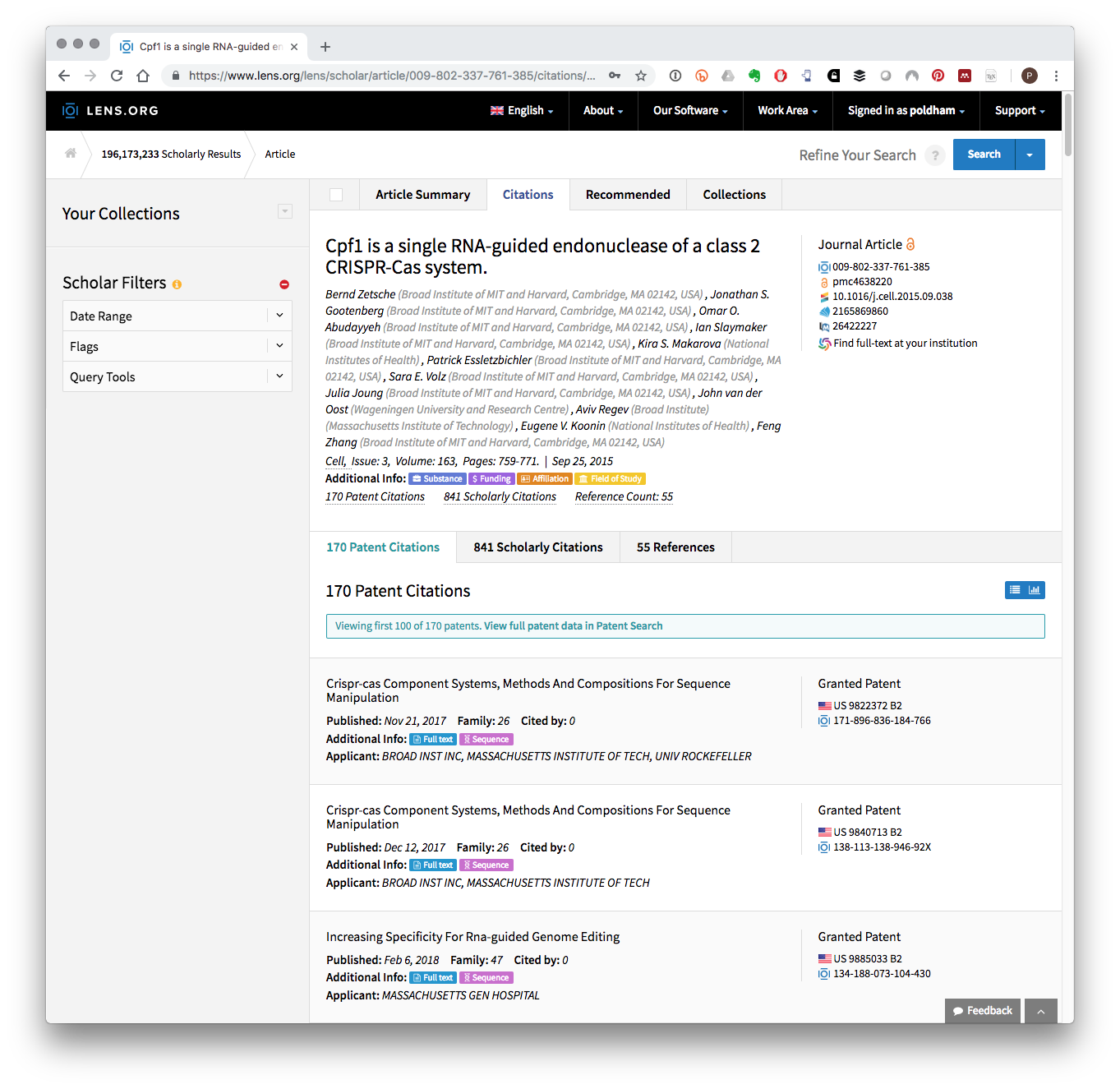
Figure 6.1: Patent Documents Citing A Key CRISPR Research Article
This suggests that one opportunity for using the cited literature identified from a raw search is to begin to build a portfolio of documents that cite key researchers in a field such as CRISPR. In the case of the four articles identified above we simply used the hyperlink to access the data, selected Patent Citations and then View full patent data. By viewing the full patent data for each link we were able to add the citing patents to a new CRISPR collection in a few minutes (you must be logged in to create a collection). At the time of writing a collection of 304 patent documents in 256 families linked to these CRISPR articles . This collection is is publicly accessible at https://www.lens.org/lens/collection/167967.
As this makes clear, linking the scientific and patent literature together makes it very easy to construct an exploratory patent portfolio in minutes. In the past this might have taken weeks or months. However, it is now also possible to work on a larger scale.
6.3 Retrieving Citations at Scale with PATCITE
The PATCITE tool in the Lens is a recent introduction that allows a user to paste in a set of article or patent identifiers to retrieve citation data. The advantage of PATCITE is that it is possible to do this in bulk at the level of thousands of identifiers, such as the widespread Document Object Identifiers (dois) for the scientific literature. This will normally be more convenient when working with data from other datasets.
To briefly illustrate PATCITE we will use the four documents identified from the CRISPR publications identified above.
“10.1038/nature21059 10.7554/elife.04766 10.1016/j.cell.2015.09.038 10.1016/j.cell.2013.08.021”
We paste these numbers into the option to Explore the cited scholarly work found in patent literature. This will then produce a screen showing the four articles and a Citing Patents list. At the time of writing this list contained 304 Members. Figure 6.2 displays the summary of results and demonstrates that it is possible to retrieve a patent portfolio based on the use of document identifiers (dois) that can then be exported (see Export results in the bottom left of Figure 6.2).
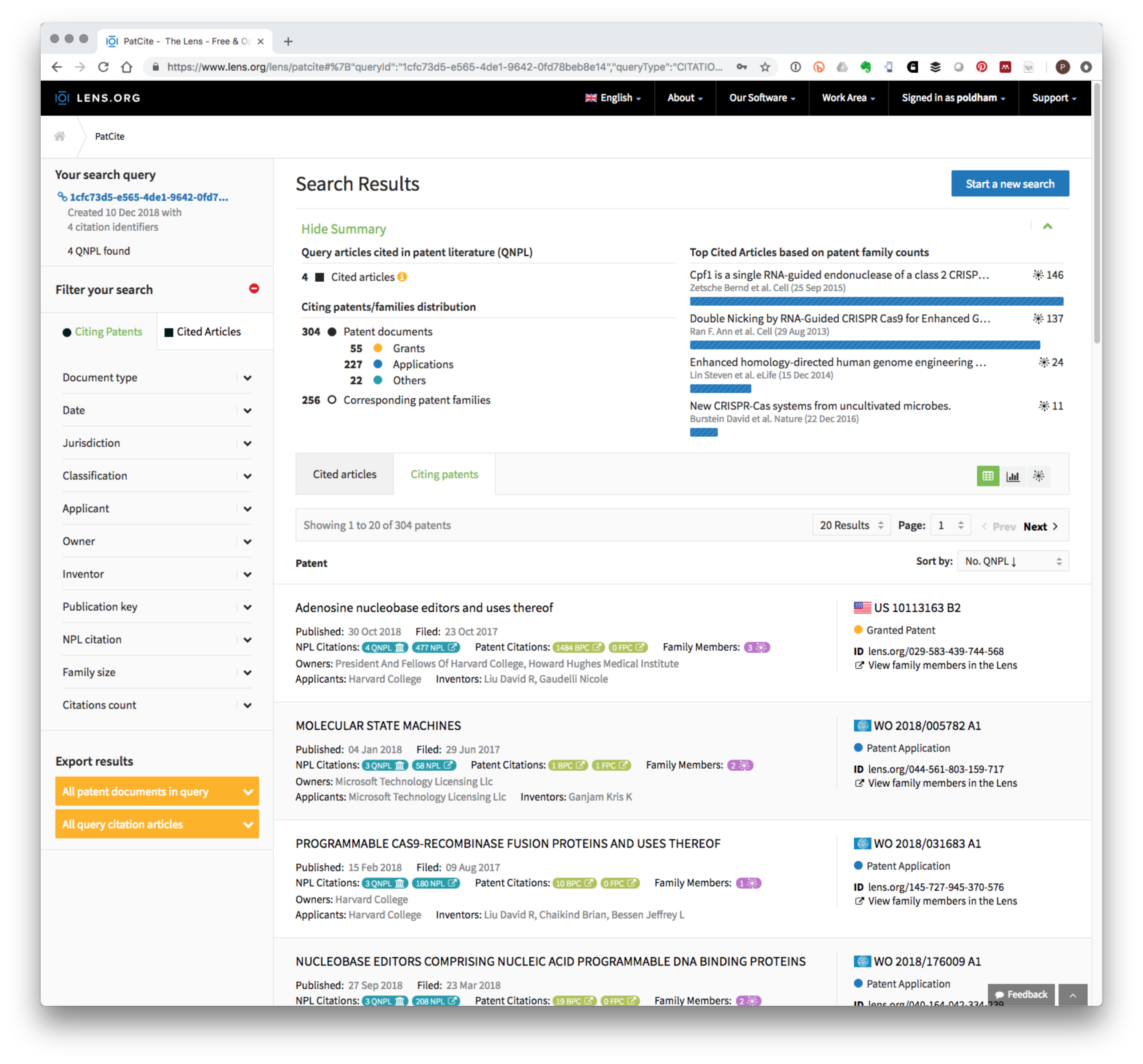
Figure 6.2: PATCITE Results for Four Key CRISPR Articles
PATCITE also features analysis tools such as rankings of applicants citing the documents and the visualisation of networks of citations. The visualisation of networks is likely to be of particular interest as it allows for the exploration of other literature cited in a patent document. By way of illustration, Figure 6.3 shows all patent citations linked to a literature record.
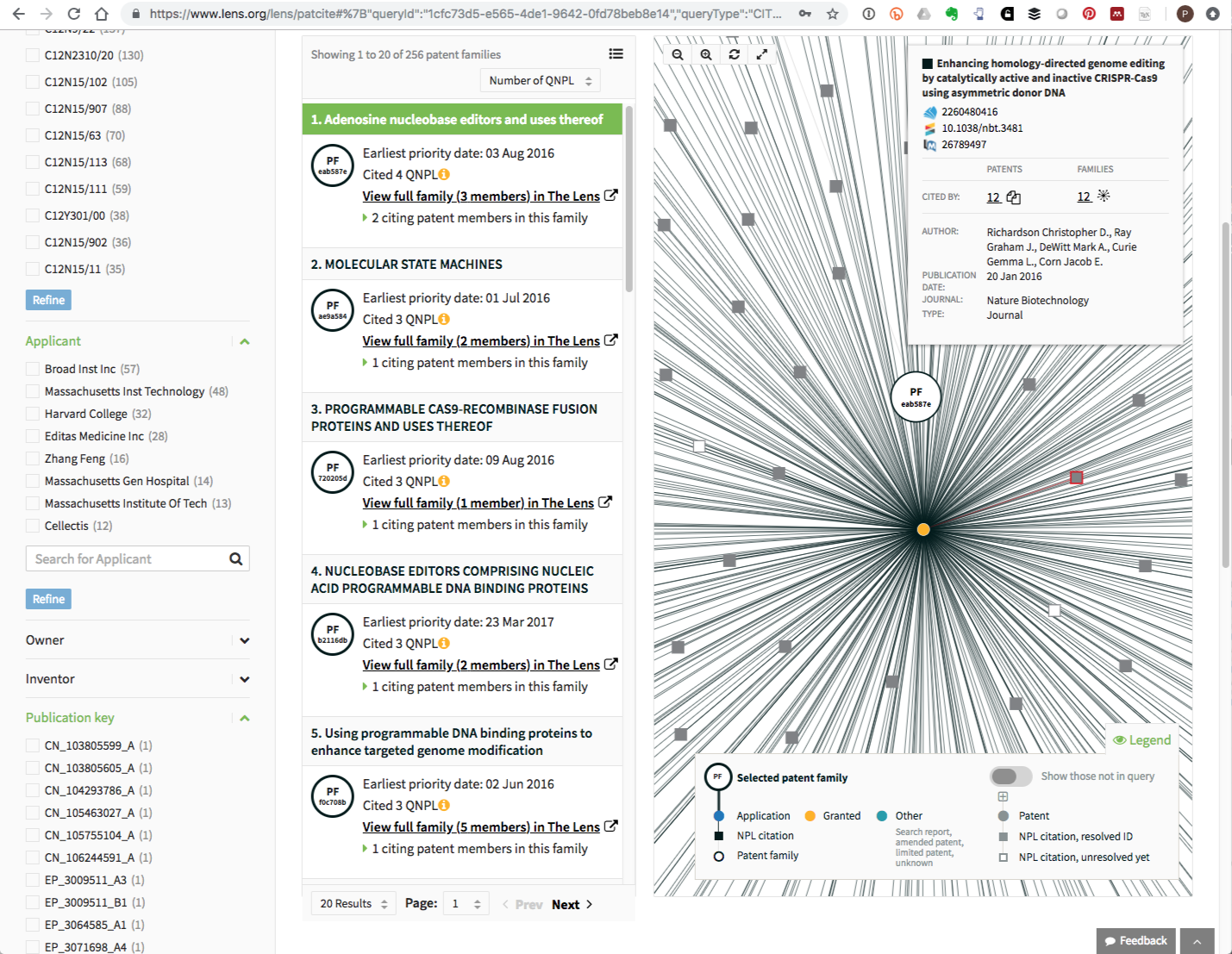
Figure 6.3: Literature Citation Network for A CRISPR related Patent Filing
PATCITE includes options to export both the cited literature (where using patent numbers as the starting point) or citing patent documents. This is particularly useful when working at a larger scale.
In recent work on synthetic biology, P. D. Oldham and Hall (2018) mapped authors of scientific articles on synthetic biology identified in Web of Science into the global patent system by matching author names to inventor names. The literature dataset on which the research was based consisted of 4,463 publications containing 3,970 dois. These dois can be accessed here if you would like to reproduce this test.
Figure 6.4 reveals that PATCITE identified 893 of the 3,970 scientific article identifiers in patent documents. Figure 6.4 displays the scientific records with the highest number of citing patent documents from a set of 2,349 patent families and 3,323 patent documents.
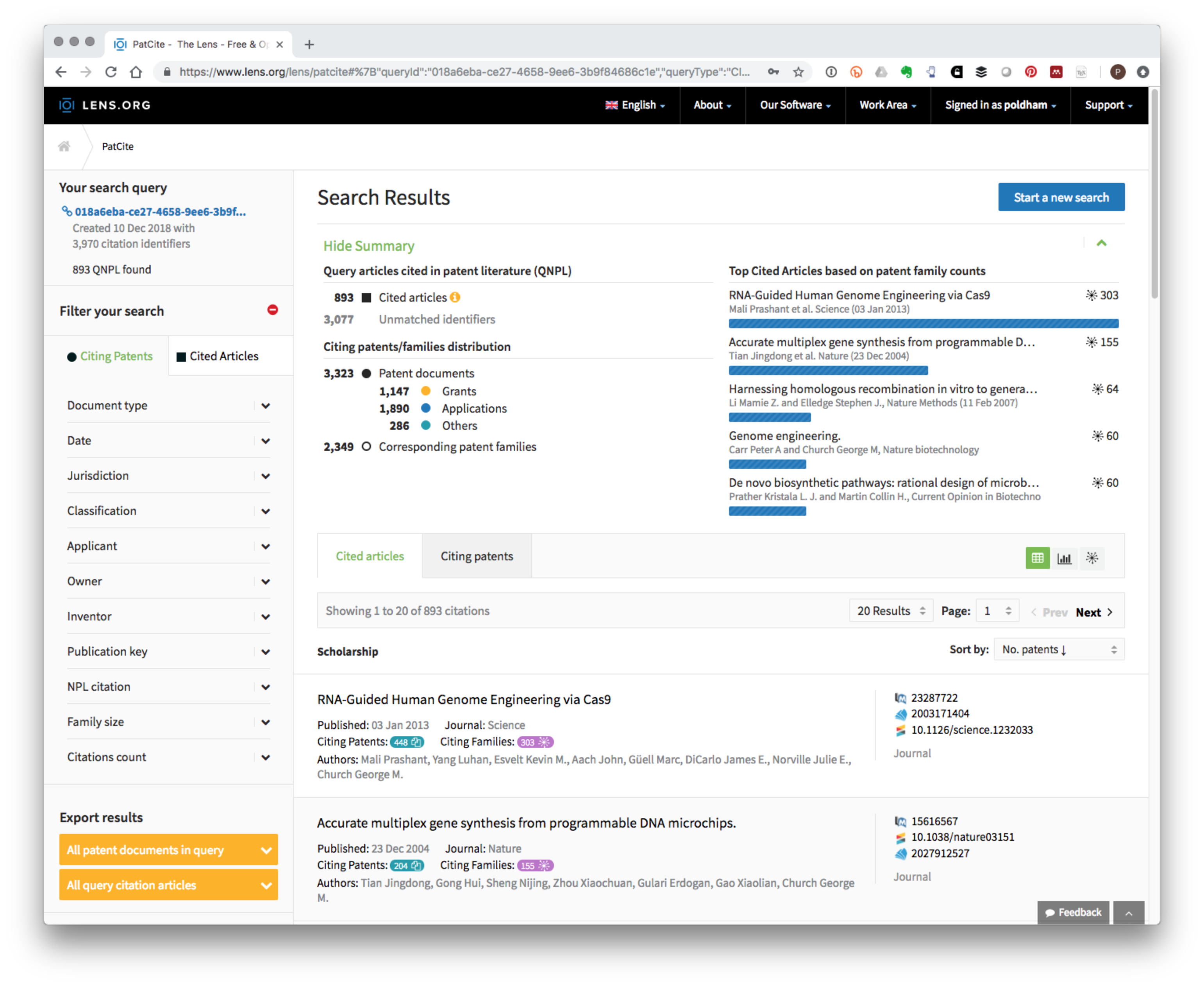
Figure 6.4: Patent Citations for Synthetic Biology Baseline Literature Dataset
Each of the datasets can be downloaded in Excel format for further analysis. As this example makes clear PATCITE addresses issues of scale in exploring the relationship between the scientific literature and the patent literature. As discussed above in the case of CRISPR this opens up the possibility of creating collections of patent data based on links with the scientific literature either as a starting point for a search strategy, mapping the impacts of research, or exploring the closeness of relationships between the scientific literature and the patent literature in innovation studies.
In the case of new and emerging areas of science and technology, such as synthetic biology PATCITE also opens up the possibility of overcoming some of the limitations of key word based searches. In the case of synthetic biology it can be argued that it is emerging within the wider field of genetic engineering and biotechnology and uses much the same language. This makes it difficult to develop a keyword strategy that adequately captures the field without capturing unrelated activity. At the same time, an additional challenge with keyword strategies is that analysts through the selection of particular terms inevitably impose their own definitions on emerging fields. For example, in the case of synthetic biology should we assume that any reference to a synthetic gene, or to protein engineering or systems biology in a patent document should be treated as synthetic biology?
PATCITE offers the possibility of beginning these explorations directly from the scientific literature and following through into the patent literature and merits serious consideration by researchers seeking to map emerging areas of science and technology in the patent system. Specifically, literature based patent searching could provide the basis for landscape construction and also be used as part of a strategy for validating the outcomes of key word based queries.
One logical question for researchers seeking to match the scientific literature into patent data is the issue of data capture. That is, it is not immediately clear whether the 3,077 dois that were not identified in PATCITE were not identified because they are absent from patent data or because of limitations in capture. The answer to this question may be a combination of the two. In practice, the ability of an analyst to interrogate data capture at the database level, such as the accurate identification of dois, is likely to be limited. However, we can gain an insight into these issues using the raw citation data from the US PatentsView service.
6.4 The US PatentsView Non-Patent Literature Table
For most patent analysts the Lens literature and PATCITE service is the logical starting point for research, for the straight forward reason that it is so easy to use and can generate a targeted patent collection for exploration within a few minutes. However, this may not suit all purposes, particularly where larger scale data is required. It is also a very good idea to have an understanding of what the raw NPL looks like in understanding the strengths and limitations of different databases.
In the case of offline patent databases such as PATSTAT a table is available containing the non-patent literature for subscribers (also accessible through the online version of PATSTAT). However, the USPTO, through the PatentsView service makes a non-patent literature table available for download (presently as a 2.7 GB tab separated zipped file).23
Engaging with the raw non-patent literature data reveals that it is a free form text field. Table 6.4 shows a sample of entries from the over 6 million entries in the 2018 USPTO PatentsView non-patent literature table.
| patent_id | text |
|---|---|
| 9339622 | English Translation of Chinese Examination Report; Application No. 2007800266164; 5 pages. |
| 5013322 | Surgery News-An Advertising supplement, Aug. 1, 1985, vol. 3, No. 15, Clayman Ovoid Model No. 8743 and Kratz/Johnson 7 mm Lightweight Model No. 8663, (2 pages). |
| 8773357 | U.S. Office Action dated Dec. 23, 2011 in U.S. Appl. No. 12/571,157. |
| 7307640 | Duke, “Dreamcast Technical Specs”, Sega Dreamcast Review, Sega, Feb. 1999, www.game-revolution.com. |
| 8543711 | Ranjan, S. and Rolia, J., Fu, H., and Knightly, E., “QoS-Driven Server Migration for Internet Data Centers,” In Proc. of IWQoS 2002, Miami, FL, May 2002. |
| 5849555 | " J. Hughes et al., ""How Does Pseudomonas Fluorescens, the Producing Organism of the Antibiotic Pseudomonic Acid A, Avoid Suicide?"", FEBS Letters, 122(2) pp. 322-324 (1980). " |
| 8811330 | Kaitz et al., “Changing the status of Subchannelization in OFDM mode,” IEEE 802.16 Broadband Wireless Access Working Group, IEEE C802.16d-03/80, IEEE, New York, New York (Nov. 13, 2003). |
| 9500933 | Jain et al., “Efficient Nonlinear Frequency Conversion with Maximal Atomic Coherence”, The American Physical Society, Physical Review Letters, vol. 77, No. 21, Nov. 18, 1996, pp. 4326-4329, 4 pages. |
| 6653062 | English Translation of Migulina. |
| 8137555 | Communication Relating to the Results of the Partial International Search for corresponding International Patent Application No. PCT/US2011/031412 mailed Aug. 9, 2011. |
| 6855523 | Biebricher, et al. (1986) Nature 321: 89-91. |
| 8960456 | Office Action issued Oct. 4, 2013 in U.S. Appl. No. 13/268,712 by Didehvar. |
| 6576467 | Feinberg et al., “A Technique for Radiolabeling DNA Restruction Endonuclease Fragments to High Specific Activity,” |
| 8735564 | Li et al; Detection of Human Papillomavirus Genotypes With Liquid Bead Microarray in Cervical Lesions of Northern Chinese Patients; Cancer Genetics and Cytogenetics, Elsevier Science Publishing, New York, NY, US; vol. 182; No. 1; Mar. 6, 2008; pp. 12-17; Abstract. |
| 9440232 | Fungi (Wikipedia.com accessed Jun. 3, 2013). |
| 9169348 | USPTO Office Action dated Sep. 9, 2008 for copending U.S. Appl. No. 11/391/571. |
| 6940750 | Jian-Gang Zhu et al. “Ultrahigh Density Vertical Magnetoresistive Random Access Memory (Invited),” Journal of Applied Physics, vol. 87, No. 9, May 1, 2000, pp. 6668-6673. |
| 8343171 | U.S. Appl. No. 60/990,062, filed Nov. 26, 2007. |
| 8046478 | MCL Paper Abstracts; Ahanger et al.; “A Language to Support Automatic Composition of Newscasts”; Journal of Compuoter Information Technology ; vol. 6, No. 3; 1998. |
| 9763641 | Ophir et al., “Elastography: Ultrasonic Estimation and Imaging of the Elastic Properties of Tissues,” Proc Instn Mech Engrs 213(Part H) (1999) 203-233. |
As we can see from this small sample of over 6 million entries in the USPTO NPL data, the individual entry fields can reasonably be described as a messy text field. Among the issues that we encounter are partial references, spelling mistakes such as “Journal of Computer Information Technology”, abbreviations such as “Proc Instn Mech Engrs” and considerable variation in the presence of dois that will all need to be addressed to successfully extract the literature references.
To extract meaningful information from this table we would need to think about identifying patterns. For example, we might look for document identifiers (dois) for the scientific literature and note that most begin with https:://doi.org. We would then discover that the references to dois within the table are limited and might switch to using titles to cross match with other databases such as Crossref or PubMed. In short, when seeking to work with the NPL data, experimentation with regular expression based pattern matching and development of a strategy would rapidly become necessary to achieve meaningful results.
To illustrate this we will use the example of web addresses in this table. While our aim is not complete accuracy in the extraction of web addresses, we can illustrate the growing relevance of web sites as sources of prior art in the US patent data.
If we were looking for web addresses we could use an approach that detects the presence of http in a reference as a distinctive string. In practice this would filter this large table down to 304,590 entries containing this term. We would then do further work to identify the domains etc. using a regular expression pattern such as www\\..*?\\.com. We could also look at modifying the regular expression pattern to capture alternative URL endings such as .org, .net etc. This is certainly doable but could rapidly become quite complicated.
An alternative approach would be to recognise that others have worked on this kind of problem before with similar types of text data. We can therefore look at using existing solutions for this particular task rather than repeating work on writing regular expression patterns. In the case of the R programming language a solution to this problem is provided by Tyler Rinkr’s recent qdapregex package in R that complements his larger qualitative data analysis package qdap. We would install and load this package as follows.
install.packages("qdapregex")
library(qdapRegex)qdapregex contains a function to extract urls from texts called ex_url() without needing to work on regular expressions. Here we create a new web object containing the text and extract the urls with ex_url() (for extract url). What we would like to do is to identify the top domain names (such as google.com) appearing in the references table.
In reality the way in which URLs are expressed in the references is quite messy and requires quite a lot of tidying up. We would probably need to do some more work to tidy up and validate the data for truly accurate results, but the code below takes us most of the way for the purposes of illustration.
library(tidyverse)
library(qdapRegex)
library(stringi)
# Our aim is to extract urls and then reduce to the domain
# ex_url returns a list object
web <- npl$text %>%
ex_url()
# process the list and return a data frame
url <- web %>%
map(., `[[`, 1) %>% # extract the first element from the list of results
discard(., is.na) %>% # drop NA for Not Available
tibble(url = .) %>% # convert to tibble
unnest() %>% # unnest list column
mutate(url = str_replace_all(.$url, "http://|https:|http|http:|:|//", "")) %>%
mutate(url = str_replace_all(.$url, "www.|>", "")) %>%
mutate(domain = sub("/.*", "", url)) %>%
mutate(domain = str_trim(domain, side = "both")) %>%
mutate(domain = stringi::stri_reverse(domain)) %>% # reverse string
mutate(domain = str_replace(domain, "^[.]|^,|^;", "")) %>% # remove junk
mutate(domain = stringi::stri_reverse(domain)) # reverse back
# count up domains and filter out blank results
domain <- url %>%
count(domain, sort = TRUE) %>%
filter(domain != "")This code parses the results down to 214,756 domains
| domain | n |
|---|---|
| web.archive.org | 12973 |
| en.wikipedia.org | 10563 |
| gsmarena.com | 3962 |
| ncbi.nlm.nih.gov | 3277 |
| ieeexplore.ieee.org | 2879 |
| youtube.com | 2834 |
| msdn.microsoft.com | 1935 |
| amazon.com | 1819 |
| microsoft.com | 1562 |
| citeseerx.ist.psu.edu | 1506 |
| w3.org | 1490 |
| ietf.org | 1428 |
| 3gpp.org | 1108 |
| research.microsoft.com | 1093 |
| clinicaltrials.gov | 936 |
| cisco.com | 922 |
| google.com | 920 |
| tools.ietf.org | 909 |
| sciencedirect.com | 857 |
| merriam-webster.com | 850 |
While this data would require further cleaning we now have a working idea of what the top web domains are across the US patent collection. In particular we can see that applicants make particular use of the Internet Archive at http://web.archive.org/ and the English language version of Wikipedia, with the third result focusing on the Global System for Mobile Communication (GSM) website GSM Arena https://www.gsmarena.com/. We can also see that in some cases such as Microsoft (or Google), specific sub-domains such as the Microsoft Developers Network (MSDN) at https://msdn.microsoft.com/en-us/ are included. If we were to do further work we would want to trim these down to the respective core domain. As this suggests, the apparently simple task of extracting and ranking web domains involves more thought than might initially be suggested. However, awareness of existing tools can radically reduce the work involved.
In this section we have seen that access to the non-patent literature in patent databases has improved dramatically in recent years. As a result of the integration of the scientific literature and patent literature by the Lens it is now possible to enter scientific literature of interest and retrieve a patent portfolio in a matter of minutes. Similar developments are taking place among commercial providers such as the subscription based Dimensions database that applies machine learning to scientific publications, grant information, clinical trials data and patent data. It is likely that other companies will be working on similar initiatives.
When coupled with other developments such as non-patent literature tables in PATSTAT and access to raw non-patent literature with PatentsView it is clear that large scale analysis of the NPL literature is now possible. The ability to work with such data at scale will typically involve programmatic skills, but it is important to bear in mind that many other fields involve finding solutions to very similar problems, such as extracting URLs from texts. Investment in research on solutions to similar problems will often radically reduce the amount of work required and allow for the detailed exploration of the non-patent literature.
We now turn to the use of patent citations.
6.5 Patent Citations
Patent citations are citations to other patent documents. They take the form of backward (cited) and forward (citing) citations. Backward citations, also referred to as back citations or cited patent documents, refer to earlier patent applications or grants that affect the scope of the claims of an application. Forward citations or citing documents refer to later filings of applications that are affected by the scope of the claims of the cited document.
Patent citations have two main sources (A. B. Jaffe and Rassenfosse 2017; Hegde and Sampat 2009):
- inventors and their patent attorneys
- patent examiners
The different sources of patent citations have important implications. Specifically, the two different sources of citations may have very different motives for including a citation (Webb et al. 2005). Thus, patent applicants and their attorneys will have an interest in disclosing references that have a limited impact on claims to novelty and inventive step. In the United States, and possibly other jurisdictions, applicants are expected to provide the prior art they are aware of as part of a duty of candour (Webb et al. 2005; Cotropia, Lemley, and Sampat 2013). This may lead to practices such as seeking to draft around the prior art (Cotropia, Lemley, and Sampat 2013). This perhaps explains why Cotropia, Lemley, and Sampat (2013) found that patent examiners typically ignore prior art provided by applicants.
In contrast, patent examiners can be expected to focus more closely on identify those that impact novelty and inventive step. Prior art searches by examiners are widely regarded as the highest quality of citations, because this involves a search by trained examiners for relevant prior art affecting an application. However, it is important to recognise that citation practices vary between patent offices (A. Jaffe and Trajtenberg 2002; Webb et al. 2005). Thus, in the United States examiners are expected to list all relevant prior art while at the European Patent Office the examination guidelines stipulate that the European Search report include only the most relevant references (Webb et al. 2005). The practical upshot of this is that citations from the USPTO will often be longer than those from the EPO. As such, it is important to be aware of the differences between patent offices in citation practices.
Bearing these issues in mind, A. B. Jaffe and Rassenfosse (2017) highlights that in broad terms patent citations provide insights in two main areas:
- the impact of inventions on other applicants and their economic and social value;
- as proxies for knowledge flows and networks.
We are now in a position to begin navigating patent citation networks.
6.7 Counting Citations by Patent Families
As we have seen above, one method or exploring the landscape of patent citations is to focus on individual documents. However, as we will now see, conducting analysis on a per document basis may miss the majority of patent citations associated with the wider patent family and the key document or documents within a family. As such counts limited to individual documents may radically underestimate the impact of a claimed invention within technology space.
We can illustrate this for our reference document EP2784162B1 and its wider INPADOC patent family. At the time of writing this document forms part of a patent family with 277 members that has 369 cited patents and 717 citing patent documents . Table 6.10 displays the top ranking publications based on citing patents within this family.
| publication_number | count_of_citing_patents | title_original |
|---|---|---|
| US8697359B1 | 274 | CRISPR-Cas systems and methods for altering expression of gene products |
| WO2014093622A2 | 157 | DELIVERY, ENGINEERING AND OPTIMIZATION OF SYSTEMS, METHODS AND COMPOSITIONS FOR SEQUENCE MANIPULATION AND THERAPEUTIC APPLICATIONS | DÉLIVRANCE, FABRICATION ET OPTIMISATION DE SYSTÈMES, DE PROCÉDÉS ET DE COMPOSITIONS POUR LA MANIPULATION DE SÉQUENCES ET APPLICATIONS THÉRAPEUTIQUES |
| WO2014093712A1 | 125 | ENGINEERING OF SYSTEMS, METHODS AND OPTIMIZED GUIDE COMPOSITIONS FOR SEQUENCE MANIPULATION | FABRICATION DE SYSTÈMES, PROCÉDÉS ET COMPOSITIONS DE GUIDE OPTIMISÉES POUR LA MANIPULATION DE SÉQUENCES |
| WO2014093655A2 | 122 | ENGINEERING AND OPTIMIZATION OF SYSTEMS, METHODS AND COMPOSITIONS FOR SEQUENCE MANIPULATION WITH FUNCTIONAL DOMAINS | FABRICATION ET OPTIMISATION DE SYSTÈMES, DE PROCÉDÉS ET DE COMPOSITIONS POUR LA MANIPULATION DE SÉQUENCE AVEC DES DOMAINES FONCTIONNELS |
| US20140179770A1 | 121 | Delivery, Engineering and Optimization of Systems, Methods and Compositions for Sequence Manipulation and Therapeutic Applications |
This data makes clear that our original reference document EP2784162B1, with 23 citing documents at the time of writing, was not reflecting the wider citation landscape for this patent family. Furthermore, as in the litigation surrounding this case discussed by Egelie et al. (2016) and Ledford (2018), the most important individual document in this family is in fact US granted patent US8697359B1. Specifically, while, as we have seen, the Broad Institute patent family cites the Berkeley patent application, in reality the Broad Institute patent attorneys used the expedited examination procedure at the USPTO with the effect that the Broad Institute patent filing was granted before the Berkeley filing was examined.^[[Source: Broad Communications 2022FOR JOURNALISTS: STATEMENTS AND BACKGROUND ON THE CRISPR PATENT PROCESS, Updated February 28]
The important insight from a patent family based perspective is that a focus on citation counts for individual documents will often miss the wider picture. As such, it is important, wherever possible, to construct citation analysis at the patent family level. This will not only assist with identifying the most important documents in a family based on citing counts but in larger datasets will allow for the identification of the most important patent families in terms of their impact upon other actors within the technology space.
When working with patent citations on a family level bear in mind that the number of family members and thus of citations will depend on the family definition. Thus, simple or DOCDB families will be smaller than INPADOC families as we have seen in the earlier discussion of Patent Families. The citing landscape for those families is therefore also likely to be smaller.
In thinking about calculating the number of citing patent documents we might be tempted to simply sum the count of citing patents provided with the export of the data from the patent database. For this working example we would obtain an answer of 5,138 as the gross figure. However, that is not actually what we want. The figure that we want is the count of distinct or unique citing documents to arrive at the citing count for the patent family.
The basic process for making this calculation is to:
- Separate out the citing patent numbers onto new rows;
- Identify any duplicate numbers.
- Remove or ignore the duplicates and count the distinct documents.
This procedure gives the correct figure of 718 citations directly linked to this patent family as we will see in the calculation below. This calculation can be performed in a number of different ways, depending on the tools you are using, with commands such as DISTINCT or unique() and so on. The important idea is to avoid over counting the citing documents by ensuring that any duplicates of the same document are not included in the count. The code below shows a step by step approach to this type of calculation in R. There will be more efficient routes to achieving this in R and other languages. The aim here is to show the steps in a transparent way. This basically consists of separating, trimming, filtering duplicates and counting.
library(tidyverse)
EP2784162B1 %>% # table containing the citing data
separate_rows(citing_patents, sep = ";") %>% # separate citing documents onto own rows
mutate(citing_patents = str_trim(citing_patents, side = "both")) %>% # trim whitespace
mutate(duplicated = duplicated(citing_patents)) %>% # identify duplicates
filter(duplicated == FALSE) %>% # filter to unique documents
select(citing_patents) %>% # choose the column to count
tally() # count| n |
|---|
| 718 |
If we were to work with a larger dataset containing multiple patent families we would therefore want to perform the above process based on each first filing (as the first family member) to arrive at the count of citing documents. Bear in mind that this choice will depend on the analytical task at hand. However, as we have seen in the case of EP2784162B1 this document is not the most important document in the family. As such, when working with patent search results it is important to move up one level to capture patent family data and then identify the most important documents in the set based on citation counts. The ability to do this will however depend in part on the options provided by the patent databases you have access to.
6.8 Patent Citations by Generation
Patent citations exist in what are often called layers or generations. Thus, a first generation forward citation is a document citing one of our reference documents such as EP2784162B1. A second generation citation is a document that cites the first generation document and so on. This is easier to appreciate where they are displayed in a tree structure. Figure 6.6 displays a tree map for PCT family members of US8697359B1. As the complete family set consists of 277 INPADOC family members we have restricted the set to PCT documents for ease of visibility. In the online version of this chapter the nodes can be selected and will expand or contract.
Figure 6.6: First and Second Generations of Citations from PCT filings for a CRISPR Family
In Figure 6.6 the first layer consists of the PCT family members of US8697359B1. Then we see the first generation of citing patents followed by a selection of the second generation of citing patents. In both theory and practice, the citation tree could extend through multiple generations until no more generations of forward citations can be identified.
An alternative way of viewing a citation tree is to cluster the records on the applicant names in the different generations. To achieve accurate results you should expect to clean the applicant names before hand. Figure 6.7 displays the same data with applicant names.
Figure 6.7: Citations from PCT filings for a CRISPR Family by Applicants
The visualisation of patent citations across multiple generations draws our attention to competitive activity in the technology space for CRISPR. However, it also draws our attention to the issue of knowledge spillovers that have been a detailed focus of analysis on the scientific literature for patent citations to which we now briefly turn.
6.9 Citations and Knowledge Spillovers
Put simply, knowledge spillovers occur where the knowledge provided by an applicant informs later inventions by other unrelated applicants that may or may not be working in the same technology space.
One way to address knowledge spillovers is to weight the citation data to remove forward citations by the same applicant. In this case the approach taken is to identify and remove any incidence of the Broad Institute from the first generation of forward citations leaving only those affected by the reference family. Figure 6.8 displays the impact of this approach.
Figure 6.8: Detecting Knowledge Spillovers
What this leaves behind therefore is other applicants. If we were to compare this family with other patent families, the applicant with the highest score in terms of knowledge spillover would arguably be the applicant with the patent family with the largest number of other applicants within the forward citing landscape.
Note that this simple approach does not address the issue of direct competitors. As we can see in Figure 6.8 the University of California (Berkeley) appears in the list of distinct applicants. It is arguably the case that viewed from the perspective of this applicant, they are the originators of the CRISPR technological breakthrough and therefore the source of the knowledge spillover. Depending on ones purpose, this could of course be settled through comparison of the patent families and counting the number of affected applicants. The “winner” in this case would be the applicant with the highest score.
An alternative, but complementary, way of thinking about how to approach knowledge spillovers would be to focus on forward citations using the International Patent Classification (IPC) or Cooperative Patent Classification (CPC). This approach would define knowledge spillovers in terms of the impacts of a claimed invention outside the technology space of the invention. That is, upon other areas of the patent system.
Figure 6.9 displays the IPC Subclasses for the documents in the source family (origin) and the first and second generations of citations.
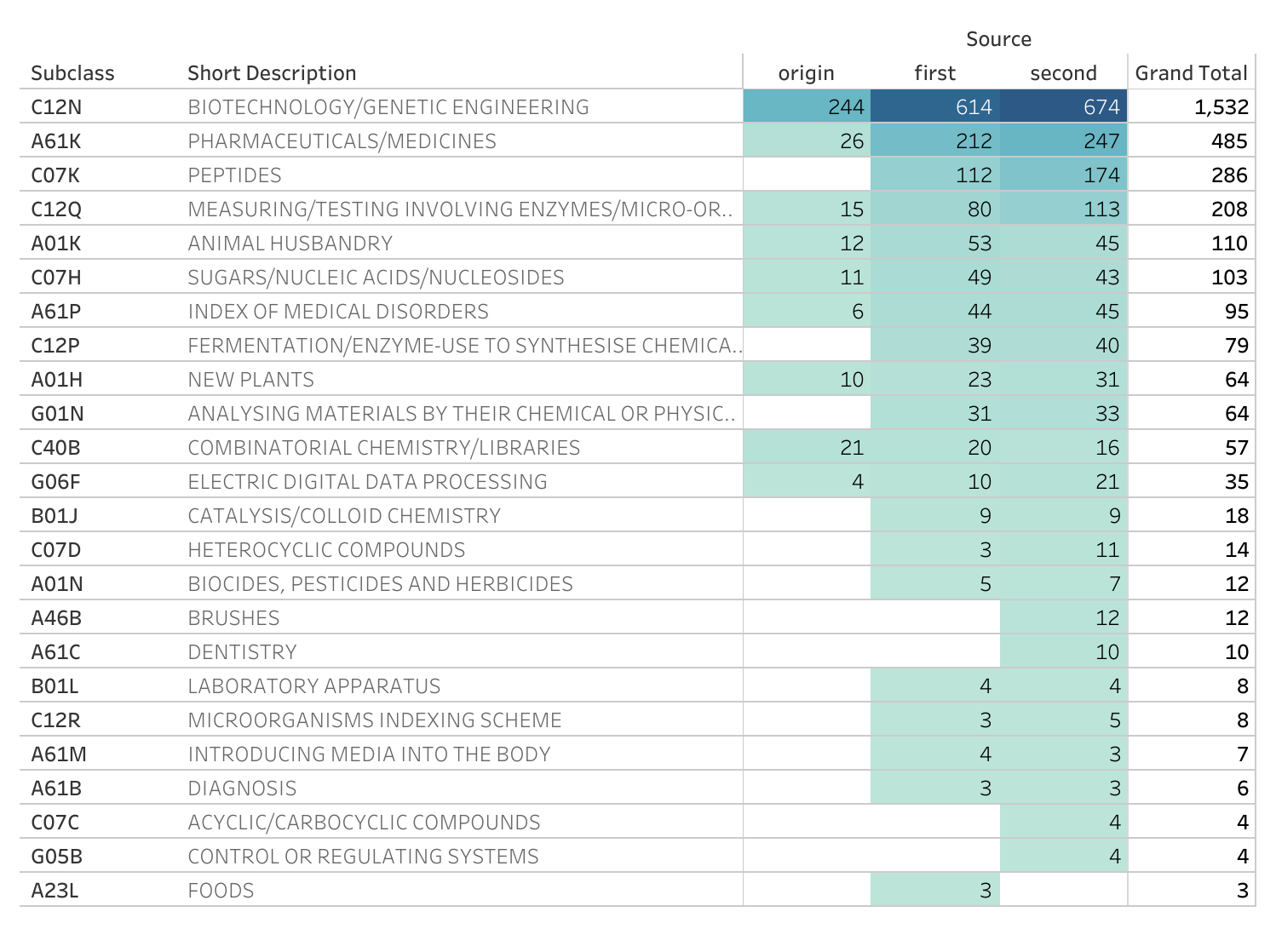
Figure 6.9: IPC Subclasses by Citing Generations
Figure 6.9 reveals that the top IPC subclass is for biotechnology and genetic engineering followed by Pharmaceuticals and Medicines. As we move from the source family into the first generation of citations (x documents) and the second generation (x documents) this pattern intensifies. As we move into the first and second generation we can see that some IPC categories actually decrease, such as new breeds of animals under A01K (for animal related biotechnology) although we would probably not want to read too much into this for the recent documents.
As noted above, one feature of citations is that a citation may be awarded for a technical feature that is not central to the claimed invention or wider technology area. In the case of the Broad Institute CRISPR patent family the appearance of IPC subclasses for brushes and dentistry reflect this. These documents in the second generation actually focus on an invention encouraging children to brush their teeth and have no relationship with CRISPR or genetic engineering. As such, we should bear in mind that apparent spillovers across generations of citations may not involve the core features of a cited invention.
Additional factors to consider when considering citations are the sources of citations. Many analysts might privilege citations awarded by examiners with an impact on the claimed invention (marked with X or Y). This would sharpen the focus of the citing network. Other factors to consider would be that patent documents are typically awarded more than one IPC class and that IPCs therefore form clusters and networks. In addition, we have focused in this discussion on the Subclass level. While this is common, it is also somewhat crude as subclasses are commonly quite broad. Thus, a more detailed IPC based analysis would look at groups and possibly specific subgroups within biotechnology (C12N) and their clusters and networks. This issue is addressed in the chapter on classification but is not further explored here.
Figure 6.9 also usefully highlights that we can detect trends or trajectories in technology classes across the generations of citations. The proliferation of IPCs across the generations of citations also suggests that a filing, or set of filings, may be part of one or more technology paths or trajectories.
At a more advanced level, citation networks and classification codes can be used for the identification of technology paths or trajectories. The analysis of technology trajectories is often traced to the work of Dosi (1982) following on from the work of Thomas Kuhn on the structure of scientific revolutions. Work by Hummon and Dereian (1989) focused on the analysis of a set of articles and scientific events that led to the development of DNA theory. Building on work by Garfield, Sher, and Torpie (1964) they used network analysis to identify the main paths between 40 events (mainly the publications of papers) that led to the identification of the structure of DNA. Whereas earlier network analysis had focused on the analysis of the nodes within the citation network Hummon and Dereian (1989) focused on the links. Specifically, by dividing a citation network into a set of sub-graphs and calculating the strength of the links between the papers across the sub-graphs they were able to use three counts of the traversal links that revealed “define the main path through the citation network” leading to the characterization of the structure of DNA and its confirmation (Hummon and Dereian 1989). Figure 6.10 reproduces the results of this analysis where numbers in the network refer to specific papers and/or events in the story of DNA.
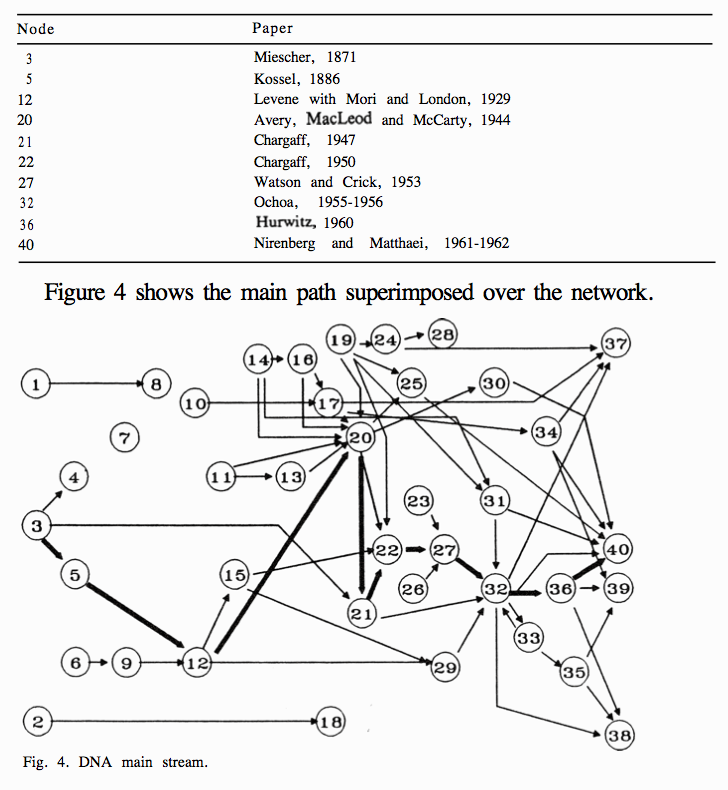
Figure 6.10: The Main Path for DNA Theory
The starting point for the main path revealed by these calculations was the Isolation of nucleic acid by Miescher in 1869 and ends with the first identification of codons producing amino acids and the role of RNA at number 40.
For our purposes, the essential issue here is that the calculation of the linkages between nodes in the network, rather than analysis of the nodes as such, can identify the key trajectory or main path in the citation network. As Hummon and Dereian (1989) points out this is similar to the calculation of the centrality of nodes in a network (which is based on calculating the shortest distance that needs to be traversed between nodes in a network).
Main path analysis has more recently been applied to patent citations. Here we will focus on the work of Christopher Magee at MIT and his collaborators whose recent work provides a good overview of the topic. In a review of existing work on main path analysis in areas such as Fuel Cells, Local Area Networks and the miniaturization of semi conductors, among others, Magee and collaborators observe that existing approaches run the risk of dropping important patents that contribute to the emergence of a technology field [ref]. This issue is also reflected in the problem that main path analysis typically identifies one main path when in practice there may be a range of paths representing contributing domains along with sub-domains within with a main path that lead to transformations (discontinuities).
The method demonstrated by Magee and collaborators consists of the following basic steps
collecting a set of patents for the technology domain. This step involves retrieving patents specific to a recognizable body of knowledge using key words, applicants or inventors. A classification overlap method (using the acronym COM) is then used to identify highly relevant documents. Essentially this step consists of identifying documents that share overlapping classifications between the now defunct United States Patent Classification (UPC) and the International Patent Classification or, in recent work, the Cooperative Patent Classification (CPC) (Park and Magee 2017; Magee et al. 2018; Benson and Magee 2012, 2014).
generating the knowledge network by retrieving the back and forward citations from the initial reference set identified above.
Measuring knowledge persistence. Magee et al argue that this is the key step in overcoming the limitations of other approaches to main path analysis using patent citation data (Park and Magee 2017). Highly persistent patents (that they call HPPs) are citations of patents that persist across multiple generations (layers) of citations in the backward and forward network. By searching both backwards and forwards they also argue that the problem of missing other paths can be overcome. They explain the concept of knowledge persistence as follows:
” The main concept of knowledge persistence is that a new invention is created by the recombination of existing pieces of knowledge and so, similar to Mendelian genetic inheritance, a proportion of knowledge in a patent is incorporated in its descendant patents. Therefore, in the patent system, cited and citing patents can be interpreted as ancestors and descendants from the genetic inheritance perspective.” (Park and Magee 2017):5
- Tracing main paths from high persistence patents. This actually consists of the calculation of the high persistence patents at the level of layers (generations) by retrieving the forward and backward sets of each patent and across the network (global).
An example of the type of analysis that results from these steps is reproduced in Figure 6.11 for the case of Solar Photovoltaic Systems (Park and Magee 2017).

Figure 6.11: Main Patent Path Analysis Results for Solar Photovoltaic Systems
When we consider the raw network of citations in the top left of Figure 6.11 and the two main paths revealed in the network, it becomes clear that one of the purposes of main path analysis is to reduce the complexity of citation networks by extracting the main path(s) that involve high persistence patents in the specific technology domain.
In recent work this type of analysis has also been applied to trace the history of the emergence of CRISPR as a breakthrough technology from underlying genome engineering technology (Magee et al. 2018). Main path analysis led them to identify three main paths,
- for cloning and restriction endonucleases,
- for core genome editing and,
- for endonucleases and related enzymes.
Figure 6.12 shows the main paths in the genome engineering data leading to genome editing.
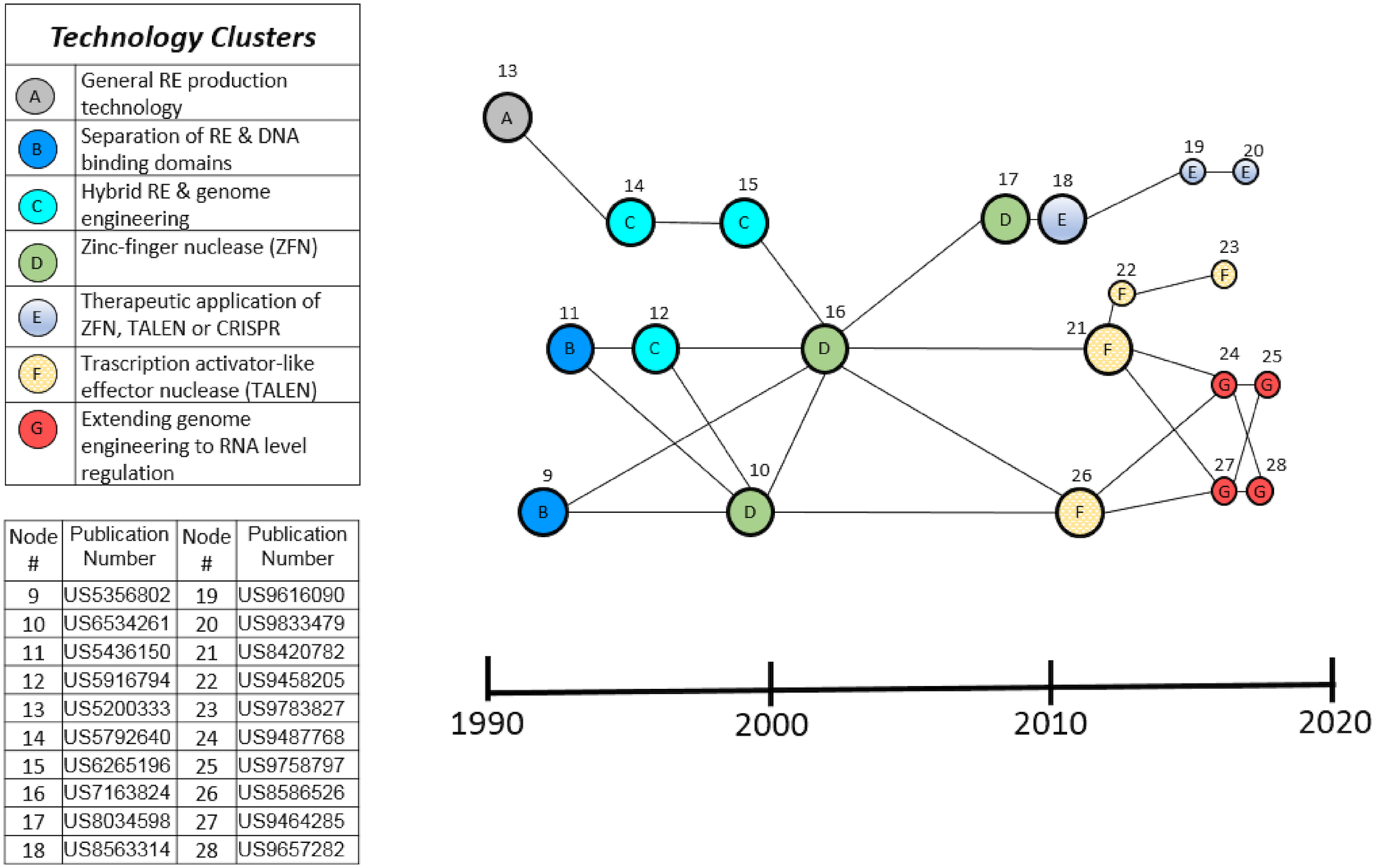
Figure 6.12: Core Genome Editing Path
In Figure 6.12 the term RE refers to Restriction Endonuclease. What this figure tells us, is that the analysis reveals that there are six clusters of activity that make up the CRISPR main path. The colours represent the technology cluster and the numbers represent the actual patent numbers. The key features of this path are that they represent advances in synthetic restriction endonucleases using zinc finger nucleases (ZFN) and transcriptor activator like effector nucleases (TALENs). These patents in relation to genome editing in the field of genome engineering are then followed, and contribute to the rise of CRISPR. Magee et al. (2018) use a separate set of CRISPR roots (based on CPC classifiers) to explore the roots of the CRISPR patents and their overlap with the earlier genome engineering patent activity presented above.
Main path analysis in the case of patent citations has emerged as an area of research for technology trajectories over the last decade or so. As the work above reveals the method continues to be refined to more accurately capture paths that contribute to an emerging breakthrough and the technological sub-clusters within an emerging technology area. The particular strength of this approach is that it reduces the complexity of citation networks and makes it easier to identify the most important paths and clusters within the network. However, a possible weakness of this method is the dependence of the classification overlap method which depends on the US classification (discontinued in 2015) and the IPC/CPC. It remains to be seen whether the use of classification codes would be as robust using purely IPC or CPC codes as a basis for selection.
Nevertheless, in drawing attention to main path analysis our purpose is to highlight that citation analysis combined with classification and citation metrics is an important field of research that increasingly promises to make navigating citation networks significantly easier. Here it is important to recall that the task of the patent analyst is ultimately to recognise complexity but also reduce that complexity to accurate information that can be communicated to the relevant audience. Main path analysis could potentially become an important feature of the analytical tool kit by identifying the main clusters and way markers influencing the trajectory of a technology area. For this reason it deserves closer critical attention.
References
To download the zipped file: [http://s3.amazonaws.com/data-patentsview-org/20180528/download/otherreference.tsv.zip][http://s3.amazonaws.com/data-patentsview-org/20180528/download/otherreference.tsv.zip]↩︎
Egelie et al. (2016) refer to this document by its family member US20140068797.↩︎